Machine data analytics, Big Data meetup
Machine data analytics, Big Data meetup
Phoenix, Arizona Feb 26th 2014An event conducted by IBM for developers. Presented about machine data analytics and their big data product Big Insight.
Big insight is more of the customized Hadoop system to fit into an enterprise environment. It has various interfaces in it making it an enterprise ready system for big data challenges.
IBM has configured the Hadoop system to be more efficient by utilizing IBM’s standard approach like replacing the event pooling system with message pooling system. Using adaptive MapReduce approach using UDP instead of the TCP messaging.
IBM utilizes various accelerators, which is an interface over its data sources like data warehouse, stream and Hadoop systems.
These accelerators helps in creating better insights, normalizes the data, indexes the data for efficient usage by other interfacing systems like visualization suites.
One of these accelerators is the Machine Data Adapter (MDA). The machine data adapter configured with templates of various standard log file structures. Out of the box, it can extract content from log files like web server log, web log and it as capabilities to create and modify these templates for the given machine data.
These templates are the configuration files, the templates can be in different file formats. Other inbuilt data source types are
- Apache Webaccess
- Delimited Separated Values, or CSV files
- Data Power®
- Generic (used when your data source type is not represented by one of the other log types)
- Hadoop Data Node
- Hadoop Jobtracker
- Hadoop Name Node
- Hadoop Secondary Name Node
- Hadoop Task Attempt
- Hadoop Task Tracker
- Syslog, or system log files
- WebSphere® Application Server
It was interesting to see how big data an ambiguous approach is now getting into a more defined enterprise solution suite. It is evident that big data is more about data in rest being utilized effective that just exploring unstructured data. This use case also demonstrates the importance of semi-structure data. When data is semi-structured, the possibility of extracting values from it is high.
I am looking forward for upcoming sessions on AQL, stream computing (real-time data analytics) sessions.
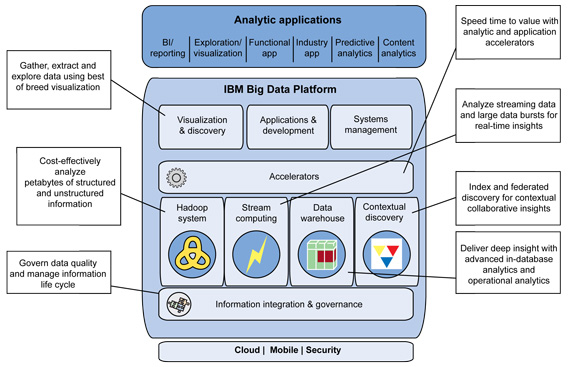
It is interesting that prediction made from data at rest used in real-time using stream analytics approach.
All the observation above, based on my understanding.